Analyzing News Articles about Food Banks
This summer, we wanted to use machine learning to analyze food insecurity caused by the economic fallout of the coronavirus pandemic.
Our first idea was to analyze Google Search Trends about food bank-related search terms. We wanted to see if the geographic distribution of trending searches would reveal where food banks were being overwhelmed, but ultimately the publicly-available data wasn’t good enough to do something like that.
We then decided to analyze news articles about food banks instead, and glean the trends from analyzing articles at scale.
We began with an initial set of over a million English news articles from the AYLIEN news tracking service. Then we filtered them to articles mentioning food banks, and related terms.
We then applied topic modelling, sentiment analysis, and (zero-shot) topic classification to analyze the articles.
Topic Modelling (Latent Dirichlet Allocation)
Topic modelling is the process of extracting clusters of topics from a collection of articles, while simultaneously determining each document’s topics.
The first analysis we performed on the dataset was to find the most prominent topic subtrends in the articles. We did this using a
Latent Dirichlet Allocation (LDA) on the articles.
This method looks at the document only as a “bag-of-words” and ignores their order. LDA represents each document as a mixture of topics which are themselves mixtures of words.
In this case the topics were not as clear cut and human-understandable as we hoped but there are some broad themes we can see.
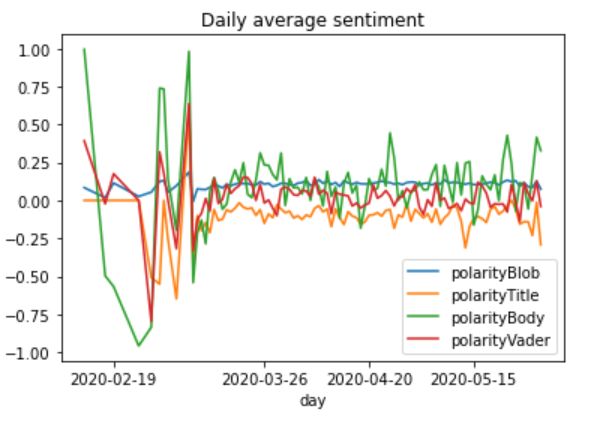
Sentiment Analysis
The next analysis we did was to figure out the overall sentiment of the articles and how it varied over time. While we expected the overall tone of coverage to be negative given the topic, we actually found that for each method of sentiment analysis we used, the articles were on average neutral.
Zero-shot topic classification
The last analysis we did was to craft our own questions/topics and track their prevalence over time.For example, we wanted to know if the articles were mentioning topics like housing insecurity, government programs, etc.
The first way we tried to address this was by reading and classifying a subset of the articles and training a natural language processing machine learning model to predict the results for the other articles. This approach did not give successful results because the data structures were too complex to analyze with the limited data we prepared.
Our next approach was to use a zero shot classifier to analyze the same questions. The Zero-Shot model can determine if a text is about a topic with no extra training.
This means that if you give the model a sentence such as “The food bank received a million dollars in donations” it can determine that it is about charity. At heart, the model is trained to solve questions about logical entailment - whether a fact supports a hypothesis. In this case, the fact is the input text, and the hypotheses were topics we chose and were interested to study for the project.
The counts are weighted by the model's confidence in the classification, i.e. an article our model gave a 95% probability of being about charity worth 0.95. We decided to plot the (relatively) 'confident' classifications (>50% probability) and 'unconfident' classifications separately.















































What we learned about food insecurity due to COVID-19 through food articles
With that said we identified surging demand for food as a much bigger problem than the food supply being insufficient, both when it came to panic buying at supermarkets and food banks struggling to meet new levels of demand. However, by April the volume of articles about panic buying decreased significantly. By June, there were no longer as many articles suggesting food banks were still experiencing overwhelming demand. On the other hand, articles about how food banks needed donations were fairly consistent at all times. We also did not notice very many articles at all about food banks closing. We also noticed interesting patterns for rent and business closures. Articles about these topics were most common around the 1st of every month at the same time that rent is due.
What we learned about machine learning
Second, we learned the value of taking time at the start of a project to explore your dataset. This includes looking manually at the data, looking for missing entries, and graphing features. This step helps frame the entire project because it helps give an idea about what correlations are in your dataset and what techniques you might need to further explore them. It also gives an intuition for how your dataset should work which makes it easier to debug your results later.
Third, we learned that open-source tools are easier to work with. Open source packages are actively maintained for feature updates and when we encountered a bug we were able to report it to the developer who patched the issue on the same day.
Comments
Post a Comment